Download
Overview
We are excited to introduce RenderMe-360, a high-quality 4D face dataset. The original data is captured 60 2K cameras on 500 subjects. And we provide diverse annotations.* Raw Data: The capturing data of each subject contains 12 facial expression videos, 6 speech videos and several dynamic motion videos with wigs (except some special performers).
* Annotation: Frame-level annotations including background matting, 2D & 3D landmarks, 3D scans, FLAME fitting model, facial attributes and action descriptions.
We provide the key raw data of 500 IDs and the full data(full raw and annotations) of 21 IDs both in GoogleDrive. To request this data part, please sign the downloaded License Agreement here, and drop an e-mail with your institution's mail address (institution, googledrive account, research purpose, etc.) to Dongwei Pan(pandongwei123@gmail.com) and CC Wayne Wu(wuwenyan0503@gmail.com) and Kwan-Yee Lin(linjunyi9335@gmail.com). We will review your application and grant Google Drive access to your account.
* Do not give one word answers such as 'testing' or 'research'. Please give a more detailed description (2~3sentences) of the intended usage. It would help us to process your request more efficiently. We'll reply the requests on every Wednesday and Friday. Thanks for your patience.
* Please check the ReadMe.txt in the same folder of data source before you use the data.
More information can be found on our official Github page.
News
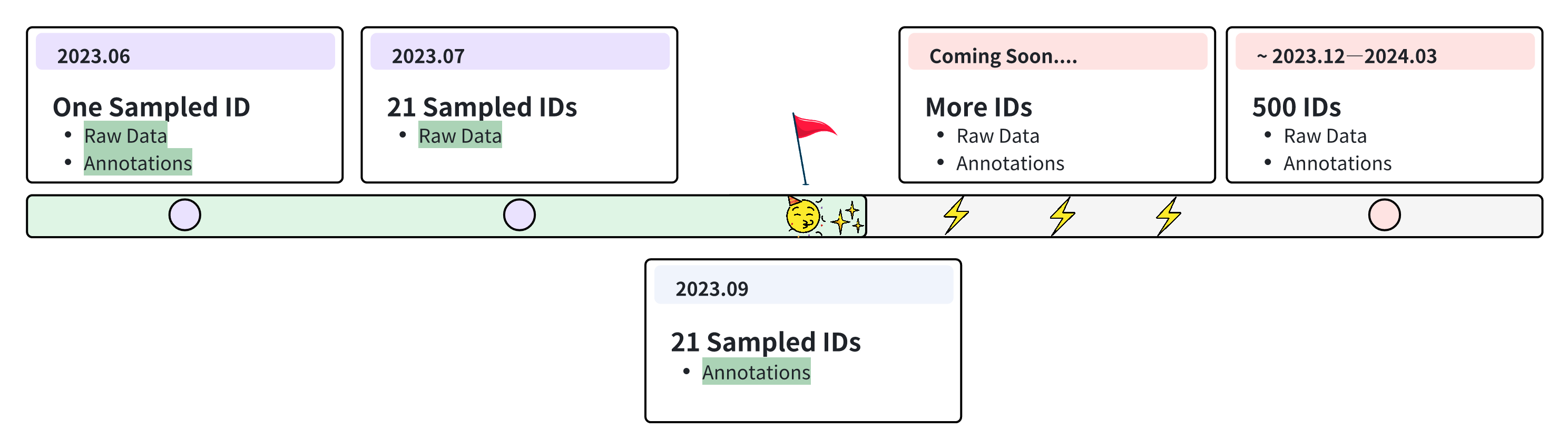
🎉 2024.06----Raw Data of 500 subjects have been released!!! To reduce the data size, we only release the key data part of each ID.🎉 2023.09----Our paper has been accepted by NeurIPS 2023 D&B Track.
🔥 2023.09----We're thrilled to announce that we have released the original raw data and corresponding annotations for 21 IDs! Please refer to the download link. Stay tuned as we finalize the remaining data.
Data Release Timeline
Our journey of data release started in June when we released the original collected data and corresponding annotations for one sample ID. In July, we have released the raw data for an additional 20 IDs. By September, we had completed the auditing and released all annotations for these 21 IDs.Looking forward, we're on track to make a significant leap - the release of full data for all 500 IDs between December 2023 and March 2024. Keep an eye on our updates as we continue to achieve our milestones.
We welcome researchers to use RenderMe-360 and contribute to the computer vision and computer graphics community. Together, let's push the boundaries of what's possible!
Current Released Contents
| Data Part | PART 1 | PART 2 | Unit Size |
|---|---|---|---|
| Subjects | 21 | 500 | - |
| RGB Cameras | 60 | 1-60 | - |
| Raw Images of Expressions |
~1,820,000 | ~7,920,000 | 2448 × 2048 |
| Raw Images of Hairstyle |
~720,000 | ~4,560,000 | 2448 × 2048 |
| Raw Images of Speech |
~6,000,000 | ~10,980,000 | 2448 × 2048 |
| Camera Calibrations | 60 | 60 | - |
| Flame Fitting | ~30,000 | - | - |
| UV Maps | ~30,000 | - | 256 x 256 |
| 2D Landmarks | ~2,135,000 | - | 106 x 2 |
| 3D Landmarks | ~140,000 | - | 73 x 3 |
| SCAN | 252 | - | - |
| Matting | ~8,540,000 | - | 2448 × 2048 |
| Facial Attributes | 2760 | - | - |
| Motion Descriptions | - | - | 4 types |
| Action Units | - | - | 12 types |
| Total Storage | 5.8 TB | ~8.3 TB | - |
Part 1: full data of 21 IDs

Part 2: key raw data of 500 IDs
To reduce the whole released data size and make it user-friendly, we deside and select the key data as described below:
1. Expression Collection: We provide 12 expressions of each ID in 60 views, but we only release the key frames of each expression.
2. Speech Collection: We provide 4 or 6 speech parts of each ID. For s3, we select the 38 views from 60views, and downsample the frames from 30FPS to 15 FPS. For the rest speech parts, we only release the frontal view data.
3. Hair Collection: We release the full data of one selected wig hair collection(60views, 30FPS) and one frame of h0 and h2 collection part.
Dataset Usage
Dataset Structure
├─ 0026_e0.smc 【smc file of expression 0】
├─ ...
├─ 0026_e11.smc 【smc file of expression 11】
├─ 0026_h0.smc 【smc file of original hairstyle】
├─ 0026_h1_[wig index + wig color].smc 【smc file of wigs, optional】
├─ 0026_h2.smc 【smc file of headgear, optional】
├─ 0026_s1.smc 【smc file of speech 1】
├─ ...
├─ 0026_s6.smc 【smc file of speech 6】
0041 【model index】
├─ ...
... 【model index】
RenderMe_360_How2Use.zip 【smc data structure】
smc_reader_renderme_360.py 【scripts for reading the smc files】
How to use - smc data structure
The foundemental element of RenderMe-360 dataset is a h5 based SMC file, named with {actorID}_{actionType}{actionID}_{sub_actionID}.smc.
Each SMC file packs 60 sets of synchronous multi-view image frames, audios (if talking), calibrations, and annotations.
The actionType includes s for speech, h for hair style and e for expression.
The actionID is the collection id.
sub_actionID is the subdivision of each collection segment (if any); where the wig collection part sub_actionID is composed as {wigID}{color}.
The top level of SMC file is organized as
{
"attrs" : atrributes of actor ID,
"Images" : multi-view image frames and audios,
"Calibration" : calibration of cameras,
"Annotation" : keypoints annotation and fitting parameters,
}
1. Basic Attributes
The attrs group stores basic attribute information of the ID, including attributes of the actor and the camera.
{
".attrs"{
"age" : int,
"gender" : str ["male", "female"],
"color" : str ["yellow", "white", "black", "brown"],
"height" : float,
"weight" : float,
}
"Camera.attrs"{
"num_device" : int,
"num_frame" : int,
"resolution" : int (height, width),
}
}
2. Videos
The Videos group contains all captured images and audios. Each image frame can be indexed by its cameraID, frameID and its type [color, mask, audio].
{
"cameraID"{
"color"{
"frameID" : uint8 (2048, 2448, 3)
...
},
"mask"{
"frameID" : uint8 (2048, 2448, 3), with BackgroundMattingV2
...
},
}
"audio": ... : uint8, exists if the action contains talking
}
3. Calibrations
The Calibrations group gives the calibration coeffient of all cameras including intrinsic, extrinisc and distortions, indexed by cameraID.
{
"cameraID"{
"K" : double (3,3) intrinsic matrix,
"D" : double (5,) distortion coeffient,
"RT" : double (4,4) maps point from camera to world
}
}
4. Annotations
The Annotations group provides the annotation of RenderMe-360 dataset labelled computed by the state-of-art methods. Specifically, Keypoint2d stores the detected 2D keypoints from all camera views. Keypoint3d provides 3D keypoints.
{
"cameraID"{
"Keypoint2d"{
"frameID" : double (frame_num,106,2)
...
}
}
"Keypoints3d"{
"frameID" : double (frame_num,73,3)
...
}
}
4.1. FLAME
The Annotations group provides the annotation of RenderMe-360 dataset labelled computed by the state-of-art methods. Specifically, FLAME stores the FLAME fitting parameters from each frame. (only in expression part)
{
"FLAME"{
"frameID"{
"global_pose" : double (3,)
"neck_pose" : double (3,)
"jaw_pose" : double (3,)
"left_eye_pose" : double (3,)
"right_eye_pose" : double (3,)
"trans" : double (3,)
"shape" : double (100,)
"exp" : double (50,)
"verts" : double (5023,3)
"albedos" : double (3,256,256)
}
}
}
4.2. UV texture
The Annotations group provides the annotation of RenderMe-360 dataset labelled computed by the state-of-art methods. Specifically, UV_texture stores the uv texture map from each frame. (only in expression part)
{
"UV_texture"{
"frameID" : uint8 (256, 256, 3)
}
}
4.3. scan mesh
The Annotations group provides the annotation of RenderMe-360 dataset labelled computed by the state-of-art methods. Specifically, Scan stores the scan mesh data. (only in expression part)
{
"Scan"{
"vertex" : double (n, 3), n: number of vertices
"vertex_indices" : int (m, 3), m: number of index
}
}
Data Interface & Visualization
We provide a standard data interface renderme_360_reader.py to fetch each data including all attributes, images, calibrations and annotations. Here is a tiny example. The code for the visualization of the annotations is coming soon....
>> from smc_reader import SMCReader
>> import numpy as np
>> reader = SMCReader('smc_file')
>> Camera_id = "01"
>> Frame_id = 0
>> audio = reader.get_audio() # Load audio
>> image = reader.get_img(Camera_id, 'color', Frame_id) # Load image for the specified camera and frame
>> print(image.shape)
(2048, 2448, 3)
>> mask = reader.get_img(Camera_id, 'mask', Frame_id) # Load mask for the specified camera and frame
>> print(mask.shape)
(2048, 2448)
>> calibration = reader.get_Calibration(Camera_id) # Load camera parameters for the specified camera.
>> print(calibration['K'].shape, calibration['D'].shape, calibration['RT'].shape)
(3, 3) (5, ) (4, 4)
>> lmk2d = reader.get_Keypoints2d(Camera_id, Frame_id) # Load landmark 2d for the specified frame. (face landmarks 106)
>> print(lmk2d.shape)
(106, 2)
>> lmk3d = reader.get_Keypoints3d(Frame_id) # Load landmark 3d for the specified frame. (33 contour points not included)
>> print(lmk3d.shape)
(73, 3)
>> flame = reader.get_FLAME(Frame_id) # Load FLAME parameters for the specified frame.
>> print(flame.keys())
['albedos', 'cam', 'exp', 'global_pose', 'jaw_pose', 'left_eye_pose', 'lit', 'neck_pose', 'right_eye_pose', 'shape', 'tex', 'trans', 'verts']
>> uv = reader.get_uv(Frame_id) # Load uv texture map for the specified frame.
>> print(uv.keys())
(256, 256, 3)
>> scan = reader.get_scanmesh(Frame_id) # Load scan mesh for the expression part.
>> print(scan.keys())
['vertex', 'vertex_indices']
More Question?
If there is something that we didn't answer here, or you are intersted in contributing/using RenderMe-360, please feel free to drop an e-mail (with your institution's mail address) to Dongwei Pan (pandongwei@pjlab.org.cn) and Long Zhuo (zhuolong@pjlab.org.cn), and CC Kwan-Yee Lin(linjunyi9335@gmail.com) and Wayne Wu(wuwenyan0503@gmail.com).Citation
@inproceedings{2023renderme360,
title={RenderMe-360: Large Digital Asset Library and Benchmark Towards High-fidelity Head Avatars"},
author={Pan, Dongwei and Zhuo, Long and Piao, Jingtan and Luo, Huiwen and Cheng, Wei and Wang, Yuxin and Fan, Siming and Liu, Shengqi and Yang, Lei and Dai, Bo and Liu, Ziwei and Loy, Chen Change and Qian, Chen and Wu, Wayne and Lin, Dahua and Lin, Kwan-Yee},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year = {2023}